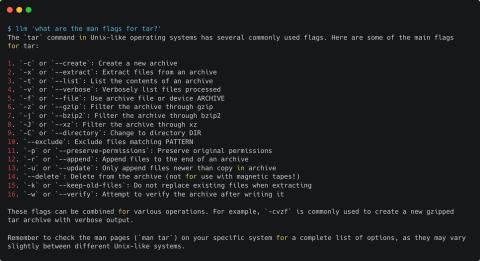
Why shouldn’t hashtag#data teams let the business query raw data and they are insisting on preparing the data?
My colleague Bo Lemmers shares her insights on the Xebia blog. The takeaways:
🐛 Misinterpreting the results is an issue. Do they know what units each column is using? Where do they find out? What if they assume and, as a result, mess up?
🔍 Missing records (or duplicated records). Without the data cleaning step, the business will get frustrated by handling these issues manually!
🐘 Slow results. When querying raw, unprocessed data, you risk scanning through billions of rows and columns that are irrelevant to your analysis!
💸 High costs. Raw data is not optimized for querying. No optimization, more money needed to query it!
⏳ Duplicate work. Every team will create their slightly different transformation, wasting hours and hours while work could have been centralized
🌦️ Misaligned decision making. If everyone is left to define key business metrics as monthly active users, there won’t be consensus around these metrics, leading to misaligned decisions.
It was a pleasure to be a guest on Tim Freestone’s Objective Hiring Podcast, talking about the Impact of hashtag#ai on Hiring.
Together, we’ve discussed how important it is—in this AI-infused time—to keep a human touch during your interview process, bias and discrimination, how to stand out, and more.
Recorded in the beautiful Xebia’s studio with a shout out at the end to - Luuk Feitsma—who taught me everything about recruitment and which I still miss every day!
When we started working with Danone in 2020, they realized data literacy was no longer a useful skill but an essential one.
Today, with hashtag#genai all around us (literally and figuratively), data literacy is even more important as knowing when and how to leverage data & AI is critical to succeed.
To help you all to get started, we’ve invited Sandra Oudshoff—who has led analytics development across 87 companies at The HEINEKEN Company—, Ronald Root—head of Data & Analytics at Van Oord—and Steven Nooijen—head of Data & AI Strategy at Xebia to discuss:
🎯 The impact of Data Literacy on your business
🎯 How a data-first mindset enhances decision-making
🎯 How to ensure your data literacy efforts are successful.
A train to Haarlem, a picturesque city in the Netherlands, on an early morning on route to deliver an Hadoop training.
There, 10 years ago, I started to prepare our first in-house training, Data Analysis with pandas.
The hashtag#Hadoop MapReduce paradigm was already in decline, as many companies realized their data would fit on a single machine. And there was nothing better than hashtag#pandas to do the wrangling!
Fast-forward to today, and our time has come to train people on Polars, the spiritual successor of pandas.
Want to know more?
Join my colleague Enrico Erler as he explains what makes Polars so special!
I can see where the market is going by seeing what my colleagues are up to, often months or years before the rest find out.
This time, it’s all about Polars 🐻❄️, and we’re organizing an in-depth webinar with Enrico Erler on October 22nd so you too can find out:
❄️How the Rust-power library leverages memory safety and performance optimization
❄️Why Polars is faster than Pandas
❄️How to get started with data transformations and filtering