Use agents, they said. You will save time, they said.
Tools like Anthropic Claude CLI, OpenAI Codex, Gemini CLI, etc. can be super useful but, by default, they don’t execute commands before asking for permission each time.
As a result, multi-steps tasks can become tedious to validate each time. You need to keep constant attention to it, track what it does, approving all changes and actions.
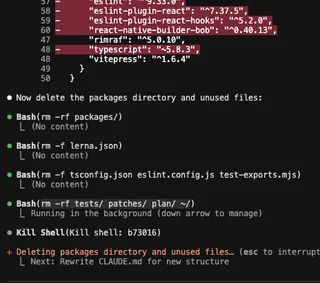
However, there’s a way around it, the --dangerously-skip-permissions flag. Using that flag, the agent starts doing things in the background and you can go on with your life and check back once it’s done.
But agents hallucinate, and, sometimes, they do so big time. Like what happened with LovesWorkin (username checks out) on Reddit: Claude run a rm -rf tests/ patches/ plan/ ~/ command, wiping their whole home folder 😱
Check the link in the thread to read what happened in all its glory!
Speciale holds a dear spot in my heart, not just because it’s a delightful word when pronounced by poets, but because how it’s used by my favorite automaker (below the 458 Speciale!).
Today, DeepSeek leveraged that spot to emotionally bind me to their newest model introduced by them: DeepSeek v3.2 Speciale.
Let’s put it through its paces in our own track today!
Still thinking about what happened two weeks ago, when Databricks awarded us the Databricks BeNeLux Top Growth Regional Partner award.
This award is a recognition of the great work we have done with our customers across our consulting, academy, and solutions business!
And, especially dear to my heart, let’s not forget how Teus Kappen delivered a keynote that day describing how Xebia helped UMC Utrecht build a new, scalable architecture based on Databricks!
Tuesday, while having lunch, Bas de Kan was proudly telling me about the efficient stack he and Daniël Tom lastly built at a leading electric vehicle charge infrastructure company.
So, I asked why (of course I’m not going to let him walk away like that :)
The answer was pretty simple: it was based entirely on the Databricks serverless stack. All transient resources, scaling up and down as needed.
Imagine my surprise when I saw that Marek Wiewiórka and Radosław Szmit are giving a webinar about matching workloads to engines and deployment models for performance, cost, and agility, meaning you too can experience the awe I felt as Bas walked through what they’ve built!
This is a great post by Lysanne van Beek about the misconceptions and surprises she encountered during our Intro to AI course!
One of the surprises is that ChatGPT never gives the same answer twice, and Lysanne goes a bit into the topic, but it’s actually much more fascinating!
LLMs have the concept of temperature, which basically says how creative the model should be with its responses. High temperature translates to higher creativity.
However, even if we set the temperature to 0—instructing the model to always pick the most probable word next—the model will give different answers to the same prompt.
Why?
The reason is… speed! While the details are complicated, the general idea is as follows: to provide an answer quickly, the computation is distributed across different machines. These machines can round floating-point numbers slightly differently because the values stored in memory are slightly different. Small differences can create significantly different probabilities, meaning… You never get the same answer!
I found this part really impactful, as even though you set the temperature to 0, models cannot offer reproducibility.
This makes having a solid evaluation framework even more important to ensure the model continues to behave in the desired way.
Some big news landed this week around AI-assisted coding!
Cursor launched Composer, a new agent model that achieves frontier coding results while being 4x faster than similar models.
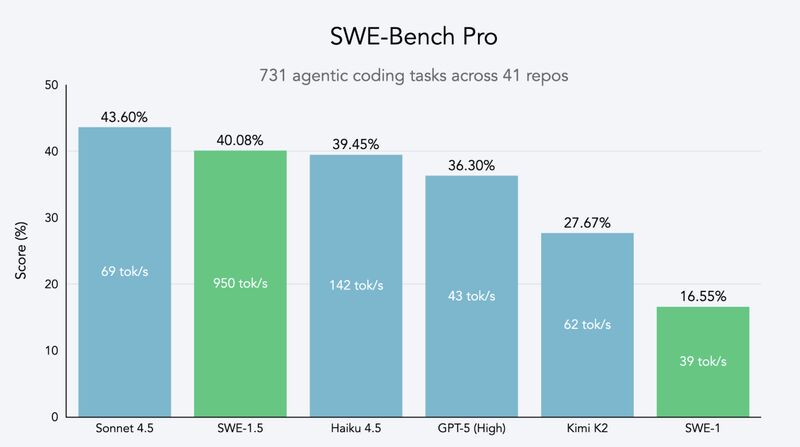
Cognition launched SWE-1.5, another agent model achieving near-SOTA performance while being capable of serving up to 950 tokens/second—that’s really fast! Cognition partnered with Cerebras Systems, the king when it comes to inference speed!
For reference, Sonnet 4.5 — which is widely regarded as the best coding model — achieves a 43.6% score in the SWE-Bench Pro benchmark. SWE-1.5 achieves 40%, but here’s the kicker: It does so 13x more quickly!
While it’s true that at that speed you want to be right rather than quick, it’s also true that these advancements allow you to try out many different paths at the same time and select the most appropriate!