October 28, 2022 at 11:32 AM
Really Google? I can’t scroll to see all emoji in Google Docs?
Really Google? I can’t scroll to see all emoji in Google Docs?
I’ve been using 1Password since version 2 (!!) and I can’t say good enough things about it.
I even got GoDataDriven | Part of Xebia on the early adopters plan once they launched their teams offering.
We do takeaway on Friday, but I think they mean something else with tradition? 🤔

bring them all and in the darkness bind them

Samsung is basically saying left-handed people should not use this

This is excellent advice to the question “How do I learn to communicate effectively?”
https://news.ycombinator.com/item?id=33094372

Sure, sign me up for it, can’t wait to give Amazon more data
https://www.amazon.com/gp/product/B09MGBK9VV/

OpenAI has just open sourced Whisper, an automatic speech recognition.
I just tried it out and I’m blown away.
Installation was a piece of cake (even though there was a missing step, but I’ve opened a pull request to help out https://github.com/openai/whisper/pull/30), and once you’re there, it literally takes seconds to start transcribing:
whisper my_file.m4a –model base
The output is ready to be used in subtitles programs as well, as it looks like this
[01:23.000 –> 01:31.000] Camilla, first question, what keeps you awake at night? [01:31.000 –> 01:36.000] Around data analytics, let’s keep it to that box [01:36.000 –> 01:45.000] Yeah, so I think we have three different, very specific business units [01:45.000 –> 01:52.000] And we have teams that are divided between being masters in data in analytics [01:52.000 –> 01:57.000] And they know much more than I do to having people who are just hearing about data [01:57.000 –> 02:00.000] And it’s a very, very scary topic [02:00.000 –> 02:08.000] And what I’m supposed to be doing is raising the level so that we at least come to the same level of understanding [02:08.000 –> 02:13.000] What does it mean for me? What does it mean for the company? What is data? [02:13.000 –> 02:17.000] I mean we really go into those type of basic conversations [02:17.000 –> 02:23.000] So that really is a challenge and an opportunity, huge opportunity [02:23.000 –> 02:26.000] So that keeps me awake at night, how do I do that?
(The audio was taken from an interview I had with Camilla Björkqvist MBA last year → https://godatadriven.com/topic/data-literacy-at-danone-investing-in-the-basics/)
https://openai.com/blog/whisper/

This is great advice and I can tell you I write a lot at GoDataDriven | Part of Xebia

A cautionary tale of A/B testing gone wrong.
If you’re reading this on LinkedIn, you probably know what A/B testing is. In its most common form, exposing your users to two variants of your site and measuring which version better performa along a set of metrics.
The winning version gets implemented.
However, what you measure makes all the difference.
Naïve teams make an assumption, and measure only metrics related to that assumption, f.e. clicks or buy-rate.
Experienced teams monitor a much wider set of metrics to ensure harm is not done elsewhere in the system.
What do you mean by elsewhere?
Let’s say this new variant of the site increases the buy-rate (e.g., we’re going to sell more items).
However, it might decrease the average margin, as more low-margin items are bought. Effectively harming the business.
It’s important to keep an eye on both.
But… even experienced teams often only monitor metrics that are very closely related to the business and not to the user experience.
What?
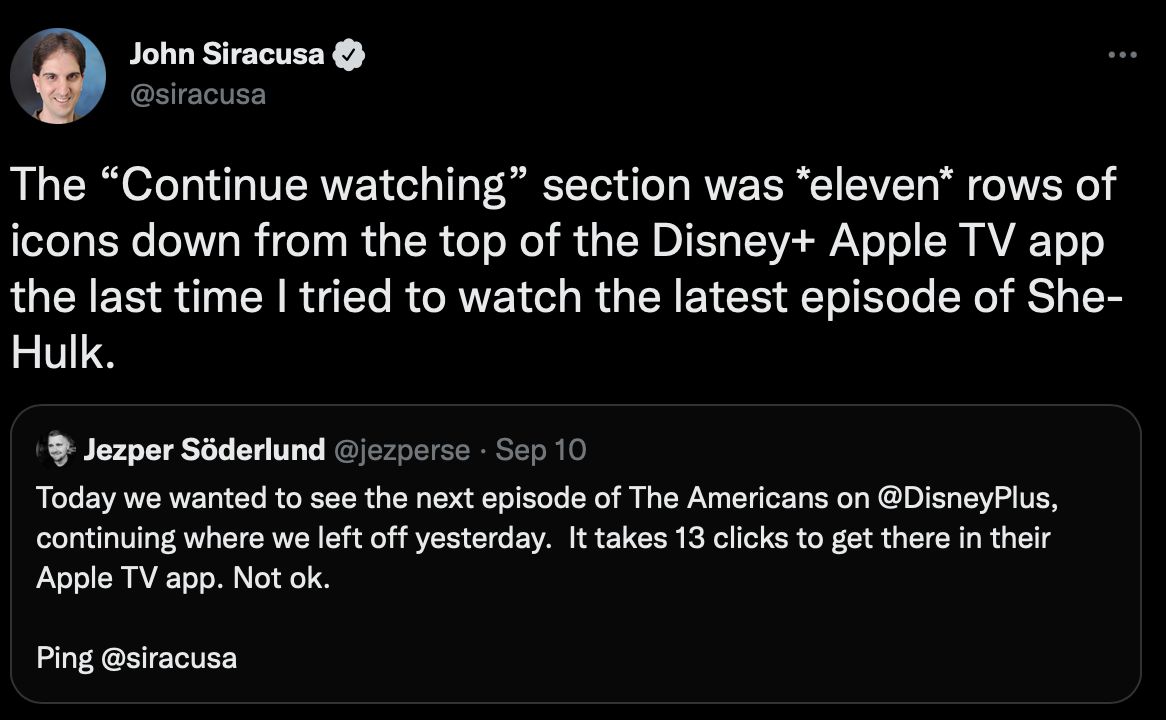
Lately there has been some commotion about how hard it is to reach the “Continue Watching” section of major streaming services (see tweet).
On the surface, it was a good decision, taken after proper A/B testing. By exposing users to different content, they might discover new stuff to watch, increasing their loyalty to your service.
But if you don’t measure the frustration of clicking 13 times, you’ll never know how harmful this new design is.
Harmful?
If I hate your app, the next chance I get to switch service or to bad mouth you, will be taken. This is 100x worse than discovering a new series when you were looking for that damn last episode.
It’s like leaving a VHS half-way in your recorder on Friday night, only to get back on Saturday night and find that someone rewound it, put it back in a place you don’t expect, and switched in a new movie you might want to watch. Maddening.
A/B test your model, but don’t forget to optimize for joy!
https://twitter.com/siracusa/status/1568719549935001602
#ml #machinelearning #abtesting
(In case you’re wondering, GoDataDriven | Part of Xebia has an A/B testing training to help you out, developed by the mighty Rogier van der Geer https://godatadriven.academy/training/a-b-testing-and-experiments-training/)